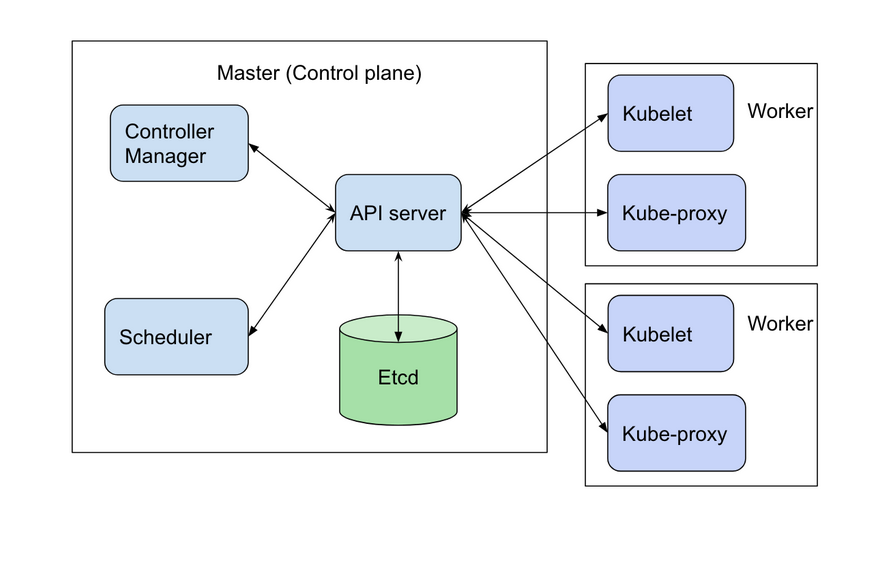
A cluster is the foundation of the Kubernetes Engine, it consists of
one or more control plane nodes (also referred to as master nodes)
and zero or more worker nodes.
It is made up of a collection of compute, networking, and storage resources
necessary to run any given workload. Communication between them is achieved
by way of a shared network.
Control plane nodes consist of a collection of services responsible for
providing the centralised scheduling, logic and management of the cluster.
The following diagram shows the relation between control plane and worker nodes:
Some of the key services running on the control plane are:
The interface to the cluster via the API server, which provides a
RESTful API frontend to the control plane.
Configuration and state of the cluster is managed by a distributed key value
store, etcd. It provides the single source of truth for the cluster and
as such is the only stateful component of the control plane.
The scheduler watches for pod creation events and binds them to a worker
node. The kubelet on that node is then responsible for starting the pod
containers.
The Controller Manager maintains the state of pods in the cluster; creating
and terminating them as required by daemonsets, deployments, replicasets
and other resources.
To allow for maximum redundancy, Kubernetes clusters should be deployed
with an odd number of control plane nodes e.g. 1, 3 or 5 nodes.
Note
While it is possible to run a cluster with a single control plane node,
for clusters intended to run production workloads, it is highly recommended
to deploy your clusters in a 3 node multi-master highly available
configuration.
All nodes run kubelet and the container runtime, containerd.
They are responsible for running the pod workloads assigned by the scheduler using
the defined local and external resources.
The Cluster Template is a collection of parameters to describe how a cluster can
be constructed. These describe the machine images to start, the Kubernetes versions,
networking environment and addon installation options.
Catalyst Cloud provide public templates for our supported managed kubernetes
customers and these should provide the flexibility you need. We recommend
that whenever possible you use the latest template, and where possible
kubernetes version we provide.
This command creates a cluster using the named template,
and 3 control plane (master) nodes and 4 worker nodes.
The name of the cluster will be dev-cluster1.
These parameters can be adjusted according to your needs.
The control plane (master) node count must be a small, uneven (odd) number.
This is to ensure the etcd distributed key-value store
has an efficient and highly available quorum available
(e.g. 4 has no benefit over 3, so is not permitted).
The values 1, 3, 5 and 7 are permitted by the API.
The worker node count can be any positive number, or zero.
Note
If you are looking to scale to a large number of nodes,
please get in touch via the Support Centre,
as there are quota and performance changes to apply at cluster creation time
for more than 50 nodes.
It is possible to override the behaviour of a template by adding or modifying
the labels supplied by the template.
Refer to the Cluster Labels appendix section for a full list of supported labels.
To do this, we need to provide the --merge-labels parameter along with the
--labels parameter followed by the desired label or labels to modify.
To specify a single label:
--merge-labels --labels key=value
You can define multiple labels by separating them into comma-separated key/value pairs.
When specifying multiple labels, ensure that there is no whitespace in the list:
--merge-labels --labels key=value,key=value
If we want to enable the master_lb_floating_ip_enabled feature on our cluster,
we would use a cluster creation command like this:
All provided cluster templates create a loadbalancer that is used to access
the Kubernetes API. By default this loadbalancer does not have a floating IP,
which limits access to only the subnet it is listening on.
This means the Kubernetes API must be accessed from a bastion host within
the same network.
If you wish to create a publically accessible Kubernetes API (for kubectl or
other tooling to use), you can do so by adding the following to the cluster
creation command.
The other field worth mentioning here is that of the health of the cluster. This
can be viewed by drilling down into the details of the cluster in the dashboard
by clicking on the link that is its name.
Alternatively, if you are working from the command line you can query the state of
a given cluster with the following command.
$ openstackcoeclustershowdev-cluster1-cname-cstatus-cstatus_reason-chealth_status-chealth_status_reason
+----------------------+------------------------------------------------------------------------------------------------+| Field | Value |+----------------------+------------------------------------------------------------------------------------------------+| status | CREATE_COMPLETE || health_status | HEALTHY || status_reason | None || name | dev-cluster1 || health_status_reason | {'cluster': 'Ready', 'infrastructure': 'Ready', 'controlplane': 'Ready', 'nodegroup': 'Ready'} |+----------------------+------------------------------------------------------------------------------------------------+
Here, status and status_reason show if the cluster is processing a request.
The fields health_status and health_status_reason are frequently updated and will surface errors
relating to the cluster such as quota or deletion failure reasons.
Once the cluster status is CREATE_COMPLETE and you have successfully
retrieved the cluster admin kubeconfig, we need to confirm that we are able to access the
cluster.
Note
The use of the bastion server is unnecessary if you created a cluster
with a loadbalancer floating ip address.
If you did not override the default behaviour you will have created a private
cluster. In order to access this, you will need to create a bastion host
within the same network to allow you to reach the Kubernetes API.
Warning
When creating a bastion server on a private network that was created by Magnum,
you will need to delete the bastion before the cluster delete can complete.
This is best done with a configuration management tool such as Terraform.
Failure to do this will result in a DELETE_IN_PROGRESS state that will not
proceed further. More information on any deletion failure can be found in the
field health_status_reason.
For the purpose of this example let’s assume we deployed a bastion host with
the following characteristics:
Name - bastion1
Flavor - c1.c1r1
Image - ubuntu-22.04-x86_64
Network - attached to the Kubernetes cluster network, with floating IP.
Security Group - bastion-ssh-access
Security Group Rules - ingress TCP/22 from 114.110.xx.xx (public IP to allow
traffic from)
The following commands check our setup and gather the information we need to set up our
SSH forwarding in order to reach the API endpoint.
Confirm that we have a security group applied to our instance that allows
inbound TCP connections on port 22 from our current public IP address. In this
case our security group is called bastion-ssh-access and our public IP is
114.110.xx.xx.
Setting up SSH forwarding is optional. You could also SSH to the bastion host,
copy the kubeconfig file, install kubectl, and run your cluster interactions from there.
Install and configure software on the bastion host
# SSH to the bastion host floating IP address
$sshubuntu@103.197.62.38
# Install tinyproxy
$sudoaptupdate
$sudoaptinstalltinyproxy
Configure tinyproxy to allow local connections and access to port 6443.
# Start port forwarding to Tinyproxy on the bastion host.
$ssh-L8888:127.0.0.1:8888ubuntu@103.197.62.38-N-q-f
# Use the Tinyproxy port as an HTTPS proxy server for subsequent commands in this terminal.
$exportHTTPS_PROXY=127.0.0.1:8888
# Start port forwarding, using the Kubernetes API address as the destination.
$ssh-L6443:10.0.0.5:6443ubuntu@103.197.62.38-N-q-f
This section shows how to manually resize an existing cluster using the Catalyst Cloud API.
Note
When using cluster auto-scaling, you instead set a minimum and maximum node
count, and the auto scaler will perform the resize actions within the provided bounds.
For more information, please refer to Auto Scaling.
Before we resize a cluster, we should review the current node count. This is visible in the Dashboard and CLI.
$ openstackcoeclustershowdev-cluster1-cnode_count
+------------+-------+| Field | Value |+------------+-------+| node_count | 2 |+------------+-------+
We can then set a new worker size on the cluster. This can handle scaling up or down.
# Resize the number of worker nodes to 4
$openstackcoeclusterresizedev-cluster14
Requesttoresizeclusterdev-cluster1hasbeenaccepted.
and we can see progress of the update, during which the cluster health will change to UNHEALTHY
(because the desired number of nodes temporarily differs from actual)
# Showing the resize in progress
$openstackcoeclustershowdev-cluster1-cname-cstatus-cstatus_reason-chealth_status-chealth_status_reason-cnode_count
+----------------------+-------------------------------------------------------------------------------------------------------------------------------------------+
|Field|Value|
+----------------------+-------------------------------------------------------------------------------------------------------------------------------------------+
|status|UPDATE_IN_PROGRESS||health_status|UNHEALTHY||status_reason|None||node_count|4||name|dev-cluster1||health_status_reason|{'cluster':'Ready','infrastructure':'Ready','controlplane':'Ready','nodegroup':"default-worker waiting on ['Ready', 'Available']"}|
+----------------------+-------------------------------------------------------------------------------------------------------------------------------------------+
# After a short amount of time
$openstackcoeclustershowdev-cluster1-cname-cstatus-cstatus_reason-chealth_status-chealth_status_reason-cnode_count
+----------------------+------------------------------------------------------------------------------------------------+
|Field|Value|
+----------------------+------------------------------------------------------------------------------------------------+
|status|UPDATE_COMPLETE||health_status|HEALTHY||status_reason|None||node_count|4||name|dev-cluster1||health_status_reason|{'cluster':'Ready','infrastructure':'Ready','controlplane':'Ready','nodegroup':'Ready'}|
+----------------------+------------------------------------------------------------------------------------------------+
In Kubernetes we can now see the additional worker nodes and pods can schedule to them.
$ kubectlgetnodes-owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIMEdev-cluster1-47ctpuwqwfsi-control-plane-a8617329-hwfvz Ready control-plane 113m v1.28.8 10.0.0.5 <none> Flatcar Container Linux by Kinvolk 3815.2.0 (Oklo) 6.1.77-flatcar containerd://1.7.13dev-cluster1-47ctpuwqwfsi-default-worker-10b73ddb-j5r2q Ready <none> 111m v1.28.8 10.0.0.4 <none> Flatcar Container Linux by Kinvolk 3815.2.0 (Oklo) 6.1.77-flatcar containerd://1.7.13dev-cluster1-47ctpuwqwfsi-default-worker-10b73ddb-k8wpw Ready <none> 111m v1.28.8 10.0.0.12 <none> Flatcar Container Linux by Kinvolk 3815.2.0 (Oklo) 6.1.77-flatcar containerd://1.7.13dev-cluster1-47ctpuwqwfsi-default-worker-10b73ddb-ljcf5 Ready <none> 67m v1.28.8 10.0.0.19 <none> Flatcar Container Linux by Kinvolk 3815.2.0 (Oklo) 6.1.77-flatcar containerd://1.7.13dev-cluster1-47ctpuwqwfsi-default-worker-10b73ddb-mbtwp Ready <none> 67m v1.28.8 10.0.0.22 <none> Flatcar Container Linux by Kinvolk 3815.2.0 (Oklo) 6.1.77-flatcar containerd://1.7.13
Kubernetes clusters can be deleted when they are no longer needed. There are
some considerations that should be made when performing this operation to avoid
unexpected costs due to certain cloud resources being preserved, or unexpected
deletion of cloud resources which are automatically discarded during the
deletion process.
Once you are certain a cluster is no longer needed, you may begin the process
of deleting it. Additional cloud resources created by Magnum during the
cluster’s lifetime (identifiable by name containing the cluster ID and/or name)
will be automatically discarded when the cluster is scheduled for deletion.
These resources are treated identically as those manually created and can be
consumed or reserved by other manually created resources. Consider checking
that none of Magnum’s resources have dependents that were manually created as
they may prevent cluster deletion from progressing:
Network resources created during cluster creation including networks,
routers, subnets, ports, security groups, etc.
$ openstacknetworklist-cID-cName
+--------------------------------------+------------------------------------------------------------------------------------------+| ID | Name |+--------------------------------------+------------------------------------------------------------------------------------------+| 6f63d4fd-d128-469c-b95a-89c2a2eadc51 | k8s-clusterapi-cluster-magnum-2a6aec5bc77990641f88801268231c63-dev-cluster1-32h3pwv26743 |+--------------------------------------+------------------------------------------------------------------------------------------+$ openstackrouterlist-cID-cName
+--------------------------------------+------------------------------------------------------------------------------------------+| ID | Name |+--------------------------------------+------------------------------------------------------------------------------------------+| 20b8693a-f8fb-4520-882a-d119fe97848c | k8s-clusterapi-cluster-magnum-2a6aec5bc77990641f88801268231c63-dev-cluster1-32h3pwv26743 |+--------------------------------------+------------------------------------------------------------------------------------------+
Load balancers from services using the LoadBalancer type. For example,
from the chosen ingress controller.
Floating IPs provisioned by Magnum. For example, those associated with the
Kube API and the ingress controller as in the example above.
$ openstackfloatingiplist-cID-c"Floating IP Address"-c"Fixed IP Address"+--------------------------------------+---------------------+------------------+| ID | Floating IP Address | Fixed IP Address |+--------------------------------------+---------------------+------------------+| 0bca9878-4076-4cdf-a1b2-2325256829c7 | 202.49.242.221 | 10.0.0.221 || ab487f0a-5fb3-428c-bce2-608dc2ced7ba | 202.49.241.238 | 10.0.0.125 |+--------------------------------------+---------------------+------------------+
Warning
Cluster deletion does not currently respect the
loadbalancer.openstack.org/keep-floatingip:"true" annotation on services
with the LoadBalancer type which only applies when the annotated service
is deleted but the cluster remains active. Floating IPs that you wish to
reuse must be disassociated with all cluster resources before cluster
deletion.
If none of the above resources are required, you may schedule the cluster for
deletion.
$ openstackcoeclusterdeletedev-cluster1
Request to delete cluster dev-cluster1 has been accepted.
The cluster and its associated cloud resources will no longer be present in
your project after a period of time. Persistent volumes provisioned by Cinder
are the exception and will be preserved after a cluster is deleted regardless
of their retention policy as these only apply during the cluster’s active
state.
$ openstackvolumelist-cID-cName-c"Attached to"+--------------------------------------+------------------------------------------+----------------------------------------------+| ID | Name | Attached to |+--------------------------------------+------------------------------------------+----------------------------------------------+| af545633-43b8-4672-91f4-d0d9f19d5153 | pvc-8c0fff36-89a9-41b0-a121-b843f7a28671 | |+--------------------------------------+------------------------------------------+----------------------------------------------+
Node groups are a means to create collections of resources that provide a way
to enforce scheduling requirements within a cluster.
When a cluster is created it already has two node groups, default-master and
default-worker. The number and type of nodes that you specify at creation time
become the defaults for each of these pools.
Resize commands that do not specify a node group are performed on the default-worker
nodegroup.
Using the openstackcoenodegroup commands we can add, modify or delete
custom node groups within our cluster.
These groups allow for customised configurations, such as node flavor that are applied
to all nodes within the node group.
Note
All nodes in a given node group are identical to one another, so any changes
to the node group configuration is applied to all nodes in the node group.
Node groups are resized with the same commands as resizing a cluster (which resizes the node group
default-worker), but we provide the --nodegroup parameter to target a different node group.
In Kubernetes 1.28 and above, the default-master node group can be resized. Before this it is not possible.
This means you can change a cluster between being a single control plane (thus, not highly available) to
having 3 or 5 control plane nodes and being highly available.
The operation is the same as resizing a worker node group:
# Make our cluster highly available, with 3 control plane nodes.
$openstackcoeclusterresizedev-cluster1--nodegroupdefault-master3
Requesttoresizeclusterdev-cluster1hasbeenaccepted.